


William Chen

William Chen is a student at University of Minnesota-Twin Cities currently completing his research at Georgia Institute of Technology under Zhigang Peng .
This project explores the moment magnitude ~7 1886 Summerville, South Carolina earthquake. Partially due to a lack of faulting on the surface, the source and nature of this earthquake has previously been difficult to ascertain. Therefore, for the purpose of elucidating the fault structure of the region, a recent deployment of seismic stations in the region has been recording continuous data since early 2021. Within this data, as well as within data from nearby permanent seismic stations, I will be identifying seismic events using both matched-filter techniques and deep-learning methods, allowing for detection of a larger number of earthquakes than manual picking alone. I will then be relocating the identified modern seismic events allowing for better observation of the fault structures of the area. Finally, these results will be compared to results of previous deployments and the source fault of the original 1886 Summerville earthquake will be more precisely identified.
Goal Reflection
August 2nd, 2022
This summer has been extremely productive for me. I got a lot more comfortable with Linux and Python and I learned a lot about techniques used in seismology. I also got a better sense of what doing research looks like and learned a lot from the graduate students and my advisor here. Lately, we’ve been working on our abstracts for the AGU fall meeting and I am looking forward to that as well. Looking back on the goals I had for the summer, I think I was successful in working towards them. Moving forward, I also hope to continue developing my communication skills and I think that the AGU conference and discussions and presentations of my research will help with that.
Overall, I am happy with what I was able to accomplish this summer. For the most part, I was able to follow through with the original goals of the project, specifically template matching and earthquake relocation, and while earthquake transformer wasn’t particularly successful, I enjoyed getting the opportunity to learn how to use it. I will also be trying to obtain some focal mechanisms in the time I have left, and I think that will be interesting as well.
Week 6 Updates
July 15th, 2022
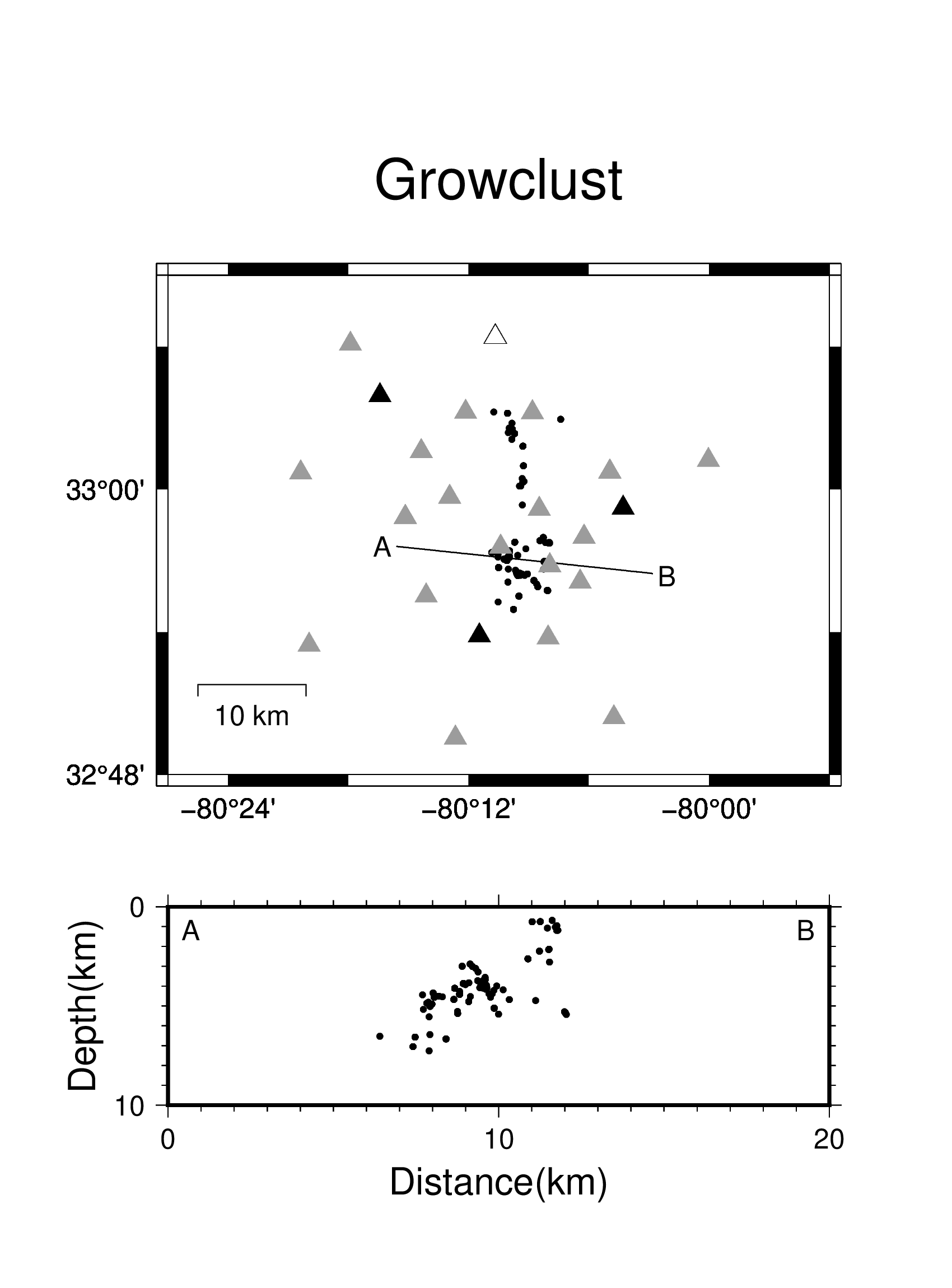
Last week I had some success with relocating the earthquakes. I used two different pieces of software to do this, xcorloc and growclust, and plotted the results. With both, the South-striking West-dipping trend found by Chapman et al. is apparent. Below is a comparison of the original template locations and the relocated detections by both xcorloc and growclust. I plotted the locations in mapview as well as on a cross-section along a N96°E-trending profile (marked A-B).
Dr. Daniels, a recently graduated graduate student, also gave me results from a 2011 dataset using hypoDD, another relocation program, and they align nicely with the growclust results. Below is a plot of the current results (in black) overlaid on the 2011 results (in grey), with both a N96°E-trending cross-section and N186°E-trending cross-section. Unfortunately, with both xcorloc and growclust, a large number of the events plotted here were not actually relocated as intended (using cross-correlation differential times), so I am still adjusting the input parameters to hopefully get more results. In the mean time I will try to apply hypoDD on the current data to see how it compares with the other results.


I have also started running EQTransformer on the data. I tested a range of different parameters on one day of data that includes a known event, but it’s been difficult to get EQTransformer to pick it out. Even when it found the event, it was only ever found on data from one station, which isn’t ideal. From there, I decided to just use one of the better setups that I had tried and run it on the entire dataset, so I’ll see how that turns out when it’s done. However, after discussing with Dr. Peng and Miguel, one of the graduate students, it seems there may not be many earthquakes that haven’t already been detected by template matching, so whether or not EQTransformer is successful is not critical.
Dr. Peng also discussed another possible avenue to explore, which is to try to determine the focal mechanisms of some of the events. This would tell us about the motion of the earth that produced the earthquake, and therefore could give more insight regarding the seismicity in the region. Dr. Zhai, another recently graduated graduate student from the department has a machine learning algorithm for automatically determining the direction of the first motion from seismograms, which would be perfect for this application.
Overall, this summer I think I have been getting better at organizing my work. I have been keeping a notebook to record what I do, trying to organize code to be more practical and adaptable, and trying to automate work when posible, and that has helped a lot with the more challenging tasks that I have encountered. Particularly with things like using EQTransformer or plotting data, I think as I progressed, I began to approach things in more thoughtful and efficient ways which helped to streamline my work.
Week 5: Example Figure
July 5th, 2022
Here is an example of one of the detections from template matching. The event had a magnitude of ~0.6 and occured on 09/08/2021 at 21:32:57. The black signal on each trace represents the signal from the continuous waveform for that day, while the overlaid red signal is the template event to which it was matched. The zero on the x-axis (in seconds) represents the time of the detection and the vertical solid black lines and solid blue lines represent the P-wave and S-wave phase arrivals, respectively (based on manual picks by Dr. Steven Jaume at the College of Charleston on the template waveforms). Traces with a signal to noise ratio of less than 3 for the template event were not plotted here, leaving all three components of four stations (WSCT, CCGC, TEEBA, and ARHS).

For a better sense of the relevance of this project, one paper that is particularly pertinent is "Modern seismicity and the fault responsible for the 1886 Charleston, South Carolina, Earthquake" by Chapman et al. in the Bulletin of the Seismological Society of America. The goal of that work was essentially the same as this current project, however it was based on a previous seismometer deployment from 2011. Based on earthquakes located by Chapman et al., an overall south-striking, west-dipping zone of seismicity was inferred. However, that trend was not entirely apparent with the data presented by Chapman et al., particularly at larger depths, so hopefully with more detections the fault structures can be better clarified.
Successes/Challenges
July 5th, 2022
So far I have been pretty satisfied with how smoothly things have been going. The template matching program was relatively straightforward to run and I have been getting more effective with the terminal, bash scripting, and python. Below is a map of the station and template event distribution. The stations, represented by triangles, are form three different networks, the temporary YH stations in gray and the permanent CO and US stations in black and white respectively. The template events that were used for matched filter detection are represented by the black dots.

I'm still working on relocating the detections and also applying EQTransformer to the data as it's taking some time to prepare all of the data to run these. For example, earthquake relocation requires calculation of differences in travel times between events which requires some preparation of the detection waveforms. Meanwhile, after going through the EQTransformer tutorial, it looks like I may have to reorganize the continuous waveform data to be sorted by station rather than the day, and convert the data from SAC files to miniseed format. Overall though, while I'm not sure how time-consuming some of these processes will be, I think I am making good progress.
Week 3 Updates
June 24th, 2022
I was able to get a number of event detections (~170) with the template matching software and I am currently going through them to see whether they are good. The next step will be to use EQTransformer, a machine learning algorithm, to try to make more detections. I have been told that previous attempts to use it on the data from this region haven't been extremely reliable, so it will be interesting to see how it goes. It may require some additional training with events from this particular dataset in order to more accurately make detections, however getting enough material to train it with could also become an issue. At the same time, I will also be working on relocating and eventually mapping the detections.
This week we also had an assignment to try to develop an elevator speech. It was definitely a useful exercise and it was helpful to try to put into words what I am doing. I think that I could always work to communicate in more engaging, understandable, and compelling ways and this is especially relevant in scenarios like giving an elevator pitch where I would want to explain what I am doing and why it is productive or valuable.
By the way, here is a picture of the computer lab Leah (the other IRIS intern here at Georgia Tech) and I have been working in. For the most part it's just us two working in here for the summer so it has been pretty quiet.

Dataset and Skill Reflection
June 21st, 2022
The data I am working with was collected from both a temporary deployment and a few permanent stations around Summerville, the region of interest. In order to apply template matching to the data to detect events, there was some processing required. Many of the stations had noise at low frequencies and around 20 Hz (as exemplified in the spectrogram below), so I filtered the data from 2-18 Hz to improve the signal to noise ratio. Another issue that came up was missing data for stations at various times. For each day of continous data provided, if one of the traces only had data for part of the day, the rest would not be searched by the template matching algorithm, so to maximize the window being searched any incomplete traces were removed.
Below is a spectrogram of one of the template events at a particular station

With regards to important skills to consider this summer, I think I would mainly like to develop communication skills. In particular, being able to communicate knowledgeably and discuss concepts properly would be beneficial for presenting work and having productive conversation about it. I think for this summer specifically, reading and learning about the background information and techniques involved in the project, as well as discussing and explaining it to different audiences will be extremely beneficial in this regard. Hopefully by the end of the summer I will be able to describe various aspects of the project more confidently and precisely.
Goals and First Week
June 10th, 2022
Going into the internship, I have several goals in mind. For the first few weeks, I’m hoping to get more comfortable and effective with Linux and Python and get used to working in the lab. I also am hoping to get more familiar with the techniques and concepts relevant to the project such as matched-filter techniques and deep-learning. Having a deeper understanding of these things will hopefully allow me to better rationalize decisions and be more active and independent in the project.
Later in the summer, I hope to develop writing and communication skills through preparing for AGU. Creating a poster and learning to talk about the project will give me opportunities to communicate ideas to different audiences which I think will be a valuable experience.
Throughout the summer, I also hope to look into and prepare for graduate school. Particularly, I want to look for different programs I might enjoy and investigate research I would be interested in doing. I also want to broaden my understanding of seismology, geophysics, and the earth sciences in general both through the project and on my own.
The orientation week and my first week have been exciting and productive. Getting to know the other interns, meeting faculty, and doing a bit of field work and coding was a lot of fun, and I think it will be nice to meet everyone again and hear about everyone’s research in the fall. Meanwhile, for my first week of the project, I have been bandpass filtering data and preparing templates for waveform cross-correlation. Hopefully, next week I can begin applying a matched-filter program to search for earthquake waveforms using the templates. I think it will be interesting to see what kind of data comes out of this.